

Scientists have designed a new artificial intelligence model that emulates randomized clinical trials to determine the treatment options most effective at preventing stroke in people with heart disease.
The model was front-loaded with de-identified data on millions of patients gleaned from health care claims information submitted by employers, health plans, and hospitals—a foundation model strategy similar to that of generative AI tools like ChatGPT.
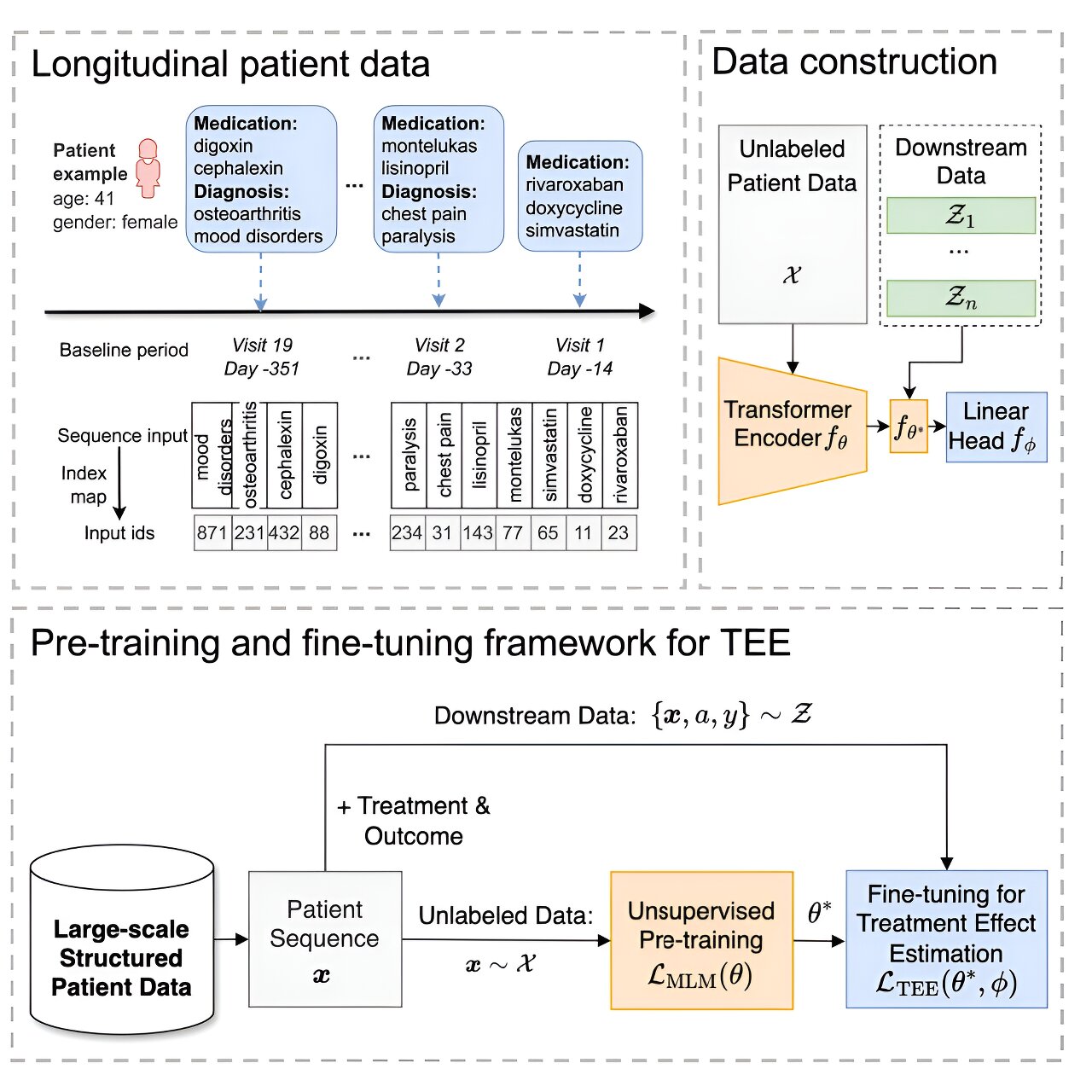
By pre-training the model on a huge cache of general data, researchers could then fine-tune the model with information concerning specific health conditions and treatments—in this case, focusing on stroke risk—to estimate the causal effect of each therapy and determine which therapy would work best based on individual patient characteristics.
The team from The Ohio State University reported in the journal Patterns that their model outperformed seven existing models and came up with the same treatment recommendations as four randomized clinical trials.
“No existing algorithm can do this work,” said senior author Ping Zhang, associate professor of computer science and engineering and biomedical informatics at Ohio State. “Quantitatively, our method increased performance by 7% to 8% over other methods. And the comparison showed other methods could infer similar results, but they can’t produce a result exactly like a randomized clinical trial. Our method can.”
Replacing gold-standard clinical research is not the point—but researchers hope machine learning could help save time and money by putting clinical trials on a faster track and supporting the personalization of patient care.
“Our model could be an acceleratory module that could help first identify a small group of candidate drugs that are effective to treat a disease, allowing clinicians to conduct randomized clinical trials on a limited scale with just a few drugs,” said first author Ruoqi Liu, a computer science and engineering Ph.D. student in Zhang’s lab.
The team dubbed the proposed framework CURE: CaUsal tReatment Effect estimation.
The beauty of a treatment effect estimation model pre-trained with massive amounts of unlabeled real-world data is its applicability to a multitude of diseases and drugs, Liu said.
“We can pre-train the model on large-scale datasets without limiting it to any treatments. Then we fine-tune the pre-trained model on task-specific small-scale datasets so that the model can adapt quickly to different downstream tasks,” she said.
Unlabeled data used to pre-train the model came from MarketScan Commercial Claims and Encounters from 2012-2017, providing 3 million patient cases, 9,435 medical codes (including 282 diagnosis codes), and 9,153 medication codes.
Two of Liu’s model-constructing techniques added to CURE’s power: filling in gaps in patient records by pairing patient information with biomedical knowledge graphs that represent biomedical concepts and relationships and pre-training a deep synergized patient data-knowledge foundation model using medical claims and knowledge graphs at scale.
“We also proposed KG-TREAT, a knowledge-enhanced foundation model, to synergize the patient data with the knowledge graphs to have the model better understand the patient data,” said Liu, who was the first author of a March Proceedings of the AAAI Conference on Artificial Intelligence paper describing the knowledge graph work.
To come up with treatment effect estimates, the model considers pre-trained data overlapped with more specific information on medical conditions and therapies and, after further fine-tuning, predicts which patient outcomes would correspond to different treatments.
As part of comparing the model to other machine learning tools and validating it against clinical trial results, the study showed that the broad pre-training is the backbone of CURE’s effectiveness—and the incorporation of knowledge graphs improved its performance further.
Zhang envisions a day—pending Food and Drug Administration approval of AI as a decision-support tool—when clinicians could use this type of algorithm, loaded with electronic health record data from tens of millions of people, to access an actual patient’s “digital twin” and let the model function as a treatment guide.
“This model is better than a crystal ball: Based on big data and foundation model AI, we can have reasonable confidence to be able to say what treatment strategy is better,” said Zhang, who leads the Artificial Intelligence in Medicine Lab and is a core faculty member in the Translational Data Analytics Institute at Ohio State. “We want to put physicians in the driver’s seat to see whether this is something that can be helpful for them when they’re making critical decisions.”
More information:
Ruoqi Liu et al, CURE: A deep learning framework pre-trained on large-scale patient data for treatment effect estimation, Patterns (2024). DOI: 10.1016/j.patter.2024.100973
Citation:
With huge patient dataset, AI accurately predicts treatment outcomes (2024, May 1)
retrieved 1 May 2024
from https://medicalxpress.com/news/2024-05-huge-patient-dataset-ai-accurately.html
This document is subject to copyright. Apart from any fair dealing for the purpose of private study or research, no
part may be reproduced without the written permission. The content is provided for information purposes only.
